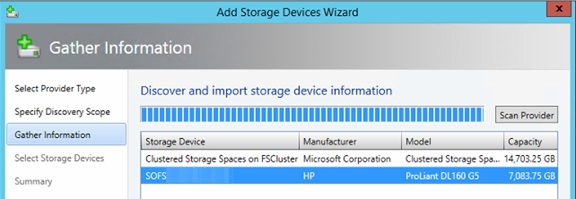
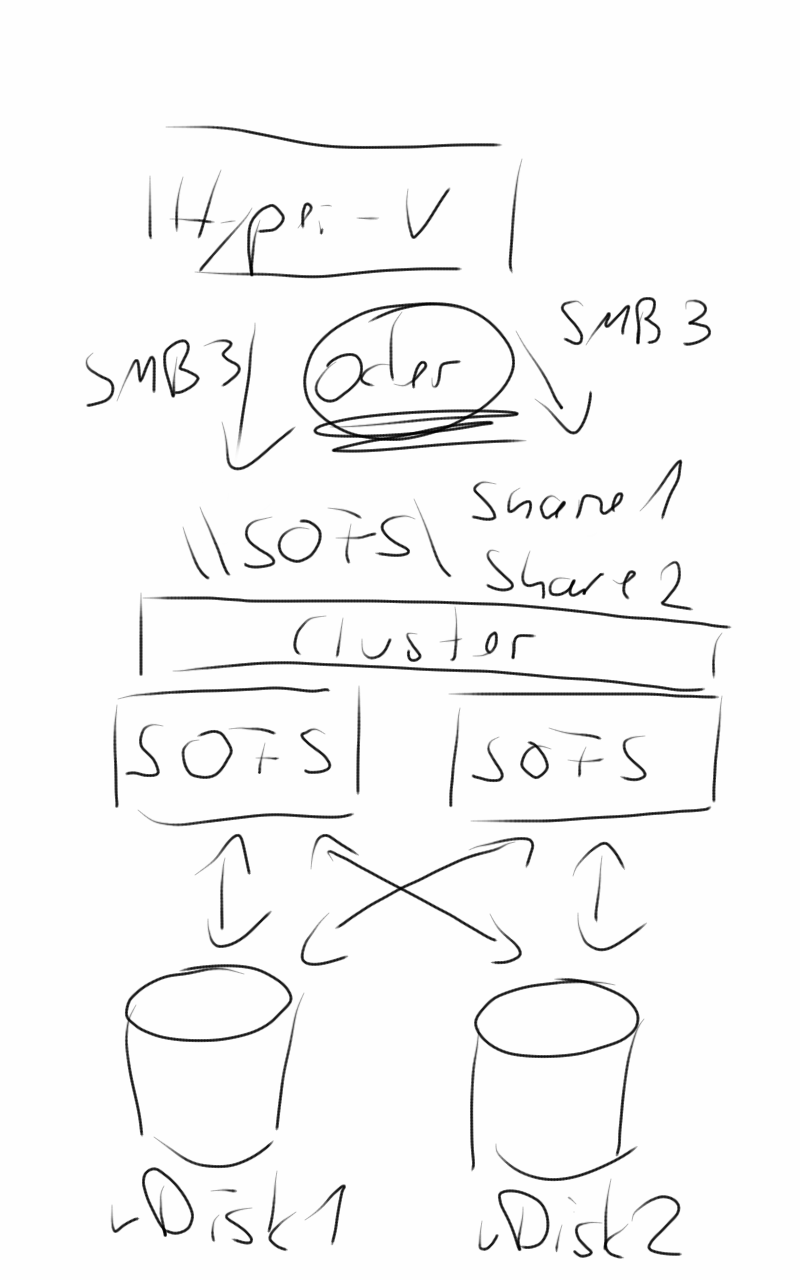
Im zweiten Teil unserer Serie möchten wir den Aufbau und die Einrichtung eines Scale-Out File Server unter Windows Server 2012 R2 zeigen. Wir nutzen für diesen Aufbau zwei Server und ein JBOD, welches mit HDDs und SSDs bestückt ist. Die Server sind HP DL360 Gen8-Systeme und haben jeweils eine CPU, 20 GB RAM und zwei lokale Festplatten für das Betriebssystem. Die Anbindung an das JBOD erfolgt per SAS, hier kommt ein Adapter von LSI zum Einsatz. Jeder Server besitzt vier 1 Gbit-Karten und zwei 10 Gbit-Karten zur Anbindung der Systeme an das Netzwerk. Als Betriebssystem kommt ein Windows Server 2012 R2 Standard zum Einsatz.
Im zweiten Teil unserer Serie möchten wir den Aufbau und die Einrichtung eines Scale-Out File Server unter Windows Server 2012 R2 zeigen. Wir nutzen für diesen Aufbau zwei Server und ein JBOD, welches mit HDDs und SSDs bestückt ist. Die Server sind HP DL360 Gen8-Systeme und haben jeweils eine CPU, 20 GB RAM und zwei lokale Festplatten für das Betriebssystem. Die Anbindung an das JBOD erfolgt per SAS, hier kommt ein Adapter von LSI zum Einsatz. Jeder Server besitzt vier 1 Gbit-Karten und zwei 10 Gbit-Karten zur Anbindung der Systeme an das Netzwerk. Als Betriebssystem kommt ein Windows Server 2012 R2 Standard zum Einsatz.
Update 04. November 2014: Wir haben diesen Artikel auf einen aktuellen Stand gebracht. Durch die Installation einiger Systeme, einigen Problemen mit gewissen Konfigurationen und weiteren Informationen, die wir erst später bekommen haben, ändert sich die Einrichtung in einigen Punkten. Alle geänderten Punkte sind in diesem Artikel farblich markiert und an der jeweiligen Stelle dazugekommen.
Update 30. Juni 2015: Ich habe den Artikel erneut geupdatet. Hinzugekommen ist eine Erweiterung des Bereichs Quorum im SOFS Cluster.
Update 14. Dezember 2015: Anpassung des Berechnung-Skripts, danke an Mike für den Hinweis
Falls Sie generell Interesse an diesem Thema haben, können wir Ihnen unseren Hyper-V PowerKurs empfehlen. Hier tauchen wir eine Woche in die Virtualisierung ein, der Aufbau und die Nutzung von SMB 3-Shares (sowohl Standalone als auch per Scale-Out File Server) spielen hier ebenfalls eine große Rolle. Mehr Informationen unter www.hyper-v-server.de/powerkurs .
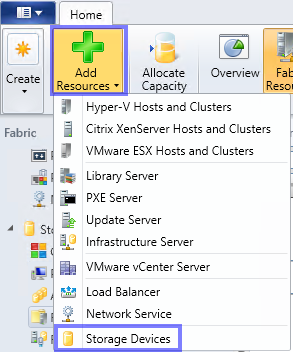
Weitere Informationen zur aufgeführten Hardware
Zu der weiter oben schon kurz beschriebenen Hardware gibt es ein paar Dinge zu sagen. Zum einen möchte ich die Hardware näher und detaillierter auflisten, zum anderen ein paar Worte zu der Anzahl der jeweiligen Komponenten sagen. Das genutzte Equipment bietet zwar die Möglichkeit einen Scale-Out File Server aufzubauen, bietet aber an einigen Stellen keine Redundanz und daher nur eine bedingte Hochverfügbarkeit. Da uns momentan “nur” diese Hardware zu Demozwecken zur Verfügung steht können wir die Best-Practice-Vorgehensweise nur bedingt in Screenshots zeigen, die Beschreibung zeigt aber die optimale Einrichtung. Lesen Sie diesen Bereich unbedingt komplett, er enthält einige Informationen zu strategischen Entscheidungen und begründet einige der Best-Practice-Vorschläge.
Die genutzte Hardware
Als Hardware kommen die folgenden Komponenten zum Einsatz:
HP DL360e Gen8
DataOn DNS-1640 JBOD mit Platz für 24 2.5” HDDs
Seagate 1200 SSD mit einer Kapazität von 200 GB
Seagate Enterprise Capacity 2.5 HDD mit einer Kapazität von 1 TB
Der optimale Aufbau
Wie bereits erwähnt ist die Anzahl der einzelnen Komponenten für eine Hochverfügbarkeit sehr wichtig. Achten Sie unbedingt auf eine Zertifizierung der Hardware, eine Liste der von Microsoft zertifizierten Komponenten ist auf www.windowsservercatalog.com aufgeführt. Der hier beschriebene Scale-Out File Server ist die Basis für einen großen Teil Ihrer IT-Infrastruktur. Wackelt dieser Teil, wackelt auch alles oben drüber. Diese Zertifizierung ist kein “nice to have”, es ist absolute Pflicht!
Die Anzahl der JBODs
Die Anzahl der JBODs, die Sie einsetzen, steht im direkten Zusammenhang mit der Verfügbarkeit und dem Verhalten beim Ausfall solch eines Geräts. Um den kompletten Ausfall eines JBODs abfangen zu können benötigen Sie insgesamt drei Stück. Dies liegt daran, dass immer mehr als 50% aller Festplatten verfügbar sein müssen. Bei zwei JBODs mit gleicher Bestückung sind bei einem Ausfall eines Geräts genau die Hälfte aller Festplatten nicht mehr verfügbar, der Scale-Out File Server ist in diesem Moment nicht mehr funktionstüchtig. Sie könnten in eins der Gehäuse mehr Festplatten/SSDs stecken wie in das andere, aber wir kennen das Problem wahrscheinlich alle: Fällt in diesem Szenario etwas aus, ist es fast immer das Gehäuse mit der größeren Anzahl an Festplatten. Ihnen hilft zu einer echten Verfügbarkeit nur ein Betrieb eines dritten (oder noch mehr, dies geht natürlich auch) JBODs. Bei drei Gehäusen sollten Sie jeweils ein Drittel aller Festplatten und SSDs in einem der Gehäuse betreiben.
Die Art des JBODs
Achten Sie bei der Auswahl Ihrer JBODs auf eine Freigabe von Microsoft. Technisch werden JBODs mit den SCSI Enclosure Services (SES) benötigt, dies bedeutet das JBOD kann den Standort der Datenträger an den bzw. die Server melden. Nur diese Funktion ermöglicht eine Speicherung von Daten auf unterschiedlichen Datenträgern in unterschiedlichen JBODs. Weiß der Server nicht, wo welche Festplatte steckt, kann er hier keinen Schutz einbringen.
Enclosure Awareness
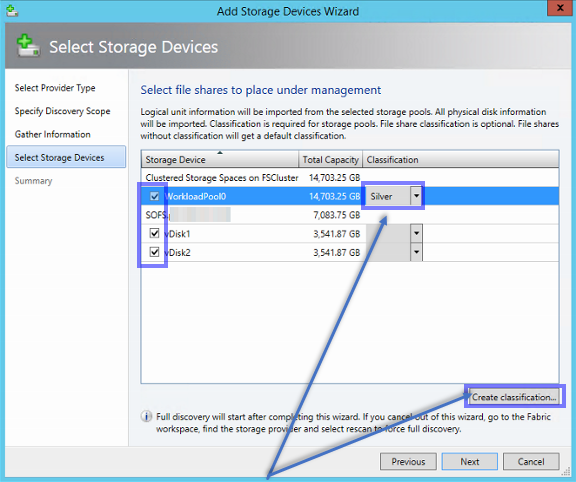
Damit Ihre Daten bei dem Betrieb von drei oder mehr JBODs vor einem Ausfall geschützt sind, müssen Sie eine Enclosure Awareness aktivieren. Dies bedeutet bei der Ablage von Daten auf Ihren Festplatten wird darauf geachtet, das die gespiegelten Daten nicht im gleichen JBOD gespeichert werden. Diese Funktion kann entweder für einen kompletten Storage Pool konfiguriert werden oder Sie setzen diese Eigenschaft bei der Erstellung Ihrer virtuellen Datenträger. Da diese Funktion nur per PowerShell aktiviert werden kann empfiehlt sich eine Erstellung von Datenträgern per PowerShell. Im späteren Verlauf des Artikels wird auf diesen Punkt erneut eingegangen. (TechNet Wiki: Enclosure Awareness Support – Tolerating an Entire Enclosure Failing)
Die Verkabelung der JBODs
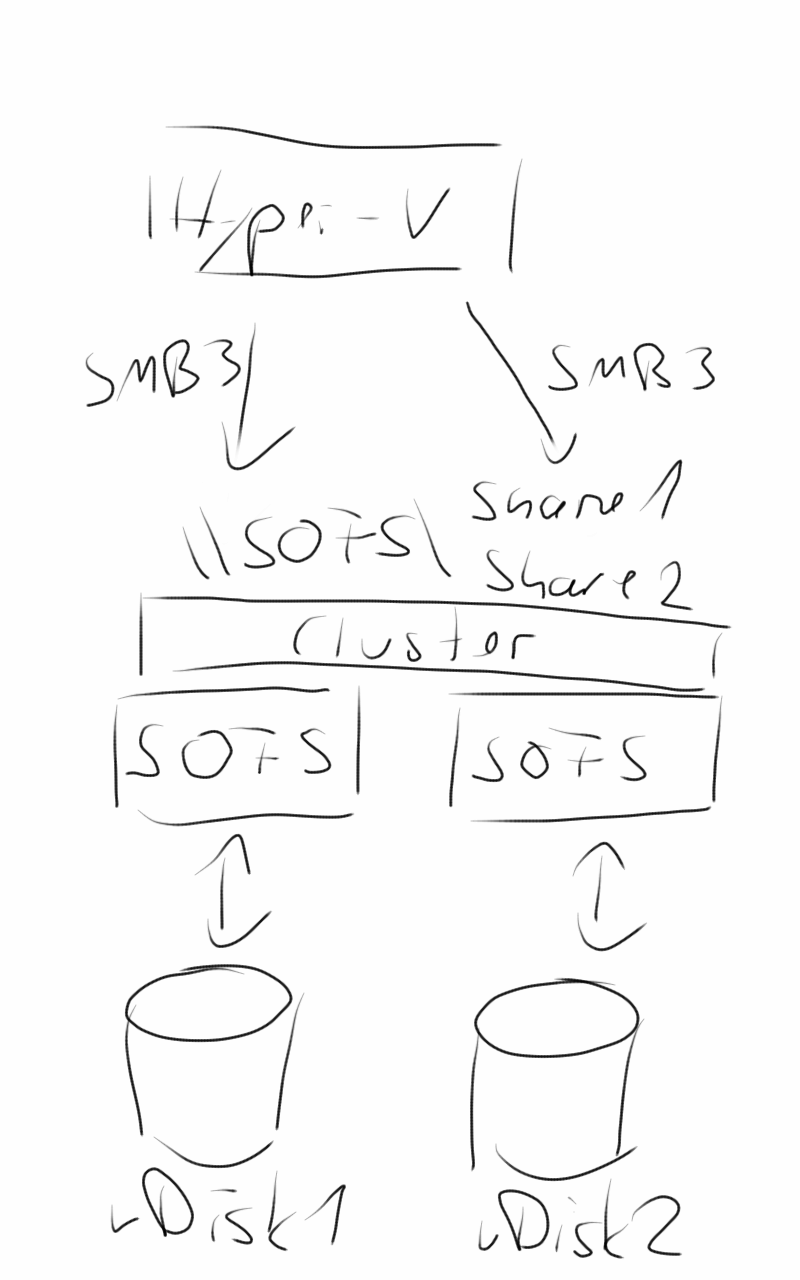
Wir empfehlen eine direkte Verkabelung der JBODs pro Server, kein Schleifen der Verbindung (Chaining) über das vorherige JBOD. Technisch ist dies natürlich möglich, Sie bauen sich aber einen möglichen Engpass und eine potentielle Fehlerquelle ein. Binden Sie jedes JBOD direkt per SAS an. Wir selbst empfehlen und konfigurieren bei unseren Kunden die Systeme so, dass jedes JBOD doppelt an jeden Server angebunden ist.
Im folgenden Bild ist ein Scale-Out File Server Knoten mit insgesamt drei Dual-Port SAS HBAs an drei JBODs angeschlossen. Mit diesem Aufbau könnte ein kompletter Controller, ein Kabel oder ein JBOD ausfallen, ohne dass die Kommunikation abbrechen würde. Der zweite Knoten wird auf die gleiche Weise verbunden. Bei Vier-Port SAS HBAs reduziert sich die Anzahl der Karten auf zwei, um alle sechs Verbindungen zu realisieren.

Die Anzahl und Größe der Datenträger
Achten Sie bei der Anzahl der Datenträger in Ihrem Failover Cluster darauf, dass Sie mindestens genau so viele Datenträger wie Knoten besitzen. Da seit Windows Server 2012 R2 eine Verbindung pro Share und nicht mehr pro Dateiserver aufgebaut wird können Sie so erreichen, dass alle Cluster-Knoten aktiv genutzt werden und nicht die gesamte Last über einen Knoten verarbeitet wird, während die anderen auf einen Ausfall warten, um übernehmen zu können. Positiv hinzu kommt, dass unter 2012 R2 eine automatische Verteilung der CSV-Datenträger im Failover Cluster passiert. Sie müssen sich nicht aktiv um die Verteilung kümmern, die Datenträger werden automatisch an unterschiedliche Knoten zugewiesen.
Achten Sie bei der Größe der Datenträger darauf, dass Sie ausreichend freien Speicherplatz im Storage Pool lassen. Nur so erreichen Sie eine schnelle Wiederherstellung der Daten beim Ausfall eines Datenträgers. Mehr Informationen dazu und wie Sie den freien Speicherplatz berechnen können finden Sie ein paar Zeilen weiter unten.
Hot-Spare-Datenträger vs. Automatische Wiederherstellung
Oft wird beim Design von einem Scale-Out File Server mit Hot-Spare Festplatten kalkuliert. Diese sind beim Einsatz von Storage Spaces zwar möglich, seitens Microsoft aber nicht vorgesehen und nicht empfohlen (Microsoft TechNet: What’s New in Storage Spaces in Windows Server 2012 R2). Die empfohlene Variante ist die Nicht-Nutzung eines gewissen Prozenzsatzes des verfügbaren Speicherplatzes, was technisch auf ein ähnliches Resultat herausläuft, allerdings auf ein deutlich schnelleres. Ein kleines Rechenbeispiel:
Sie nutzen in Ihrem Scale-Out File Server mehrere SSDs und HDDs, die HDDs haben eine Größe von 4 TB. Sie haben eine weitere 4 TB Festplatte als Hot-Spare Datenträger konfiguriert. Ihnen fällt nun eine 4 TB Festplatte aus und die Daten auf der ausgefallenen Festplatte müssen nun auf den Hot-Spare Datenträger übertragen werden, damit der Spiegel wieder intakt ist. Bei einer Transferrate von 100 MegaByte pro Sekunde haben Sie eine Wiederherstellungszeit von 40000 Sekunden bzw. 11,1 Stunden. Diese Zeit wird natürlich nur benötigt, wenn die kompletten 4 TB beschrieben sind, bei einer geringeren Datenmenge nimmt die Dauer ab.
Microsoft hat bei Nutzung der Storage Spaces ein etwas anderes Verfahren genutzt, um die Daten beim Ausfall eines Datenträgers wiederherzustellen. Falls ausreichend Platz vorhanden ist werden die Daten, die auf der defekten Festplatte lagen, auf alle anderen verfügbaren Datenträger kopiert. Dies bedeutet es müssen nicht 4 TB auf eine Festplatte allein zurückgeschrieben werden, sondern eine gewisse Anzahl an Festplatten bekommt jeweils z.B. 100 GB. Da alle Festplatten gemeinsam “ihre” 100 GB speichern müssen ist der Gesamtzeitraum der Wiederherstellung deutlich geringer als bei der Wiederherstellung auf einer Festplatte.
Bei der Berechnung des freien Speicherplatzes gehen wir davon aus, dass alle Festplatten und alle SSDs die gleiche Kapazität haben. Die Berechnung muss separat für HDDs und SSDs gemacht werden, jeder Speicher muss einen eigenen freien Speicherplatz haben. Den freien Speicherplatz errechnen Sie wie folgt:
((Gesamter Speicherplatz/Anzahl der Datenträger) + 8GB) * Anzahl der Enclosure
Diesen freien Speicherplatz ziehen Sie von Ihrem Gesamt-Brutto-Speicherplatz ab. Im späteren Verlauf der Einrichtung sehen Sie, wie diese Formel bei der Berechnung des freien Speicherplatzes genutzt wird, um sowohl freien HDD- als auch freien SSD-Speicherplatz zu berechnen.
Update: Wir haben bei der Nutzung von freiem Speicherplatz zur Ausfallsicherheit einige Probleme gehabt. Während einer Wiederherstellung der Daten sind die Datenträger in dem entsprechenden Pool so stark beschäftigt, das dies die gesamte Performance des Storage negativ beeinflusst. Dies liegt daran, dass ein Storage Pool ohne Anpassung mit der RepairPolicy auf Parallel steht.

Dies bewirkt zwar eine sehr schnelle Wiederherstellung, allerdings auch eine sehr hohe Belastung. Man könnte an dieser Stelle die RepairPolicy umstellen auf Sequential, dies käme dann aber eher dem HotSpare-Gedanken nahe. Aus diesem Grund haben wir uns entschieden, in unseren Projekten aktuell ausschließlich auf HotSpare-Datenträger zu setzen, nicht auf freien Speicherplatz. Dies beeinflusst wieder die Anzahl an Datenträgern, die benötigt werden, um auf eine gewisse Anzahl an Coloums zu kommen. Mehr dazu etwas weiter unten.
Die Art der Spiegelung
Sie können grundsätzlich zwischen drei Arten Datenträgern wählen: Simple, Mirror oder Parity. Simple ist eine einfache Speicherung der Daten ohne Schutz vor einem Ausfall, bei Mirror werden die Daten gespiegelt und bei Parity nutzen Sie eine Parität ähnlich einem RAID5, um die Daten bei einem Ausfall von einem Datenträger trotzdem noch lesen zu können. Bei der Nutzung von Storage Spaces inkl. Tiering (wird etwas weiter unten erklärt) können Sie nur Simple oder Mirror wählen, Parity ist hier nicht möglich. Da Simple in den wenigsten Fällen zum Einsatz kommen wird konzentrieren wir uns in unserem Fall ausschließlich auf Mirror. Seit dem Windows Server 2012 R2 können Sie neben einem Zwei-Wege-Spiegel (Ein Block wird auf einem Datenträger abgespeichert und gleichzeitig auf einen weiteren gespiegelt) auch einen Drei-Wege-Spiegel aufbauen. Hierbei wird ein Block auf einem Datenträger gespeichert und zusätzlich auf zwei weitere Datenträger gespiegelt.
Nutzen Sie nach Möglichkeit immer einen Drei-Wege-Spiegel. Dies mag auf den ersten Blick als Verschwendung gelten, es gibt aber einen äußerst guten Grund für diese Art der Spiegelung: In einem Storage Space werden die Blöcke nicht wie bei einem RAID1 immer nur auf zwei Datenträgern abgespeichert, sondern die Daten liegen auf allen Festplatten verteilt. Dies führt dazu, dass im schlimmsten Fall in einem Zwei-Wege-Spiegel der Ausfall von zwei Datenträgern ausreicht, um einen Datenverlust zu erzeugen. Wird eine Enclosure Awareness genutzt können theoretisch alle Datenträger in einem JBOD ausfallen, danach aber kein weiterer mehr in einem der anderen JBODs. Wir empfehlen ausdrücklich die Einrichtung eines Drei-Wege-Spiegel, da hier zumindest zwei Festplatten ausfallen können, ohne das es zu Datenverlust kommt! (TechNet Wiki: What are the resiliency levels provided by Enclosure Awareness?)
Die Blocksize / Interleave der virtuellen Datenträger
Achten Sie bei der Erstellung und Formatierung der virtuellen Datenträger (bei der Nutzung als Ablage für Hyper-V VMs) darauf, dass Sie eine Blockgröße (im englischen Interleave genannt) von 64k verwenden. Dieser Wert ist optimal bei Nutzung als Ziel für Hyper-V VMs. Wie genau Sie diesen Wert konfigurieren zeigen wir Ihnen im späteren Verlauf bei der Konfiguration der virtuellen Datenträger.
Die Anzahl der Columns / Spalten
Die Anzahl der Colums bestimmt, über wie viele Datenträger die Daten gleichzeitig pro Verbindung weggeschrieben werden. Egal ob Sie nur HDDs, nur SSDs oder eine Mischung aus beidem haben, es gibt pro virtuellem Datenträger nur einen Column-Wert. Ein paar Beispiele:
- Sie haben zwei Festplatten in einem Zwei-Wege-Spiegel und ein Interleave von 64KB. Sie haben einen Column-Wert von 1, d.h. Sie können pro Vorgang 64KB abspeichern (diese werden dann auf beide Festplatten geschrieben).
- Sie haben vier Festplatten in einem Zwei-Wege-Spiegel und ein Interleave von 64KB. Sie haben somit einen Column-Wert von 2, d.h. Sie können pro Vorgang 2x 64KB abspeichern (zwei Festplatten nehmen jeweils 64KB an, zwei weitere speichern eine Kopie dieser Daten).
- Sie haben 22 Festplatten und zwei SSDs in einem Zwei-Wege-Spiegel mit einem Interleave von 64KB. Sie haben in dieser Konfiguration einen Column-Wert von eins, da der kleinste Wert pro Datenträger-Typ diesen Wert bestimmt. Pro Vorgang können maximal 64KB abgespeichert werden.
- Sie haben 18 Festplatten und sechs SSDs in einem Zwei-Wege-Spiegel mit einem Interleave von 64KB. Sie haben somit eine Column-Anzahl von 3 und können pro Vorgang 3x 64KB abspeichern.
Diese Beispiele sollen Ihnen aufzeigen, dass nicht die Größe der SSDs bzw. HDDs ausschlaggebend sind, sondern die Anzahl. Teilweise sehen wir Konfigurationsvorschläge mit zwei 800 GB SSDs und vielen HDDs. Hier wären acht 200 GB SSDs deutlich besser. Die Column-Anzahl von eins bedeutet nicht, dass immer nur zwei Datenträger genutzt werden. Pro Vorgang werden zwei Datenträger genutzt, d.h. wenn Sie acht VMs betreiben kann jede auf jeweils zwei Datenträger schreiben (wenn der Spiegel mit kalkuliert wird, es können trotzdem nur 64KB geschrieben werden).
Bei einem Drei-Wege-Spiegel ändert sich die Berechnung ein wenig, dies kommt daher das pro Interleave drei HDDs bzw. SSDs benötigt werden. Zwei weitere Beispiele:
- Die haben neun HDDs und drei SSDs in einem Drei-Wege-Spiegel mit einem Interleave von 64KB. Sie haben eine Column-Anzahl von 1, da die drei SSDs diese Zahl erwirken. Gleichzeitig können 64KB verarbeitet werden pro Vorgang.
- Sie haben 24 HDDs und 12 SSDs in einem Drei-Wege-Spiegel mit einem Interleave von 64KB. Mit diesem Aufbau erreichen Sie einen Column-Wert von 4, bedingt durch die geringere Anzahl an SSDs.
Bei einer automatischen Erstellung der Datenträger ist die maximale Anzahl an Coloums der Wert 8, mehr werden nicht automatisch genommen. Bei der Erstellung der Datenträger per PowerShell können Sie auch einen höheren Wert auswählen. Sie müssen nicht grundsätzlich immer 8 oder mehr erreichen, Column-Werte ab 3 sind OK, falls möglich sollten Sie 4 erreichen. Alles über vier ist super, rechtfertigt aber meist nicht der erhöhten Preis für weitere SSDs (da diese in den meisten Fällen die geringe Anzahl in der Gesamtmenge ausmachen, aktuell noch bedingt durch den Preis).
Auf den Seiten von Microsoft ist eine Grafik abgebildet, die den Performance-Unterschied zwischen 2 und 4 Columns zeigt:

Quelle: TechNet Wiki: Storage Spaces – Designing for Performance
(TechNet Wiki: What are columns and how does Storage Spaces decide how many to use?)
Die Nutzung von Tiering
In der vorherigen Kapiteln wurde häufig von der Nutzung von HDDs und SSDs gleichzeitig gesprochen, hier folgt nun eine Erklärung dieser als Tiering bezeichneten Möglichkeit, die seit Windows Server 2012 R2 existiert.
Ein Pool kann unter 2012 R2 aus zwei unterschiedlichen Arten von Datenträgern bestehen, HDDs und SSDs. Hierbei ist es egal wie schnell die Festplatten sind, alle SAS-Festplatten werden als HDD behandelt. Grundsätzlich macht nur der Betrieb von Festplatten der gleichen Geschwindigkeit Sinn (z.B. immer NearLine-SAS HDDs mit 7.2k rpm). Neben HDDs können noch SSDs eingebunden werden, hier funktionieren ebenfalls nur SAS-SSDs, keine Consumer-Produkte.
Die Daten in den virtuellen Datenträgern werden vom Scale-Out File Server analysiert und je nach Nutzung entweder auf die SSDs verlagert (wenn festgestellt wird, dass die Daten häufig in Nutzung sind) oder auf den HDDs gespeichert (wenn festgestellt wird, dass die Daten nicht häufig benutzt werden). Das Betriebssystem arbeitet hier grundsätzlich mit 1 MB großen Blöcken, d.h. es werden nicht immer komplette Dateien verschoben, sondern nur 1 MB große Stücke der Datei.
Standardmäßig werden die Daten nachts um ein Uhr umsortiert, Grund hierfür ist ein Task auf den Datei Server-Knoten:

Weitere Informationen über den technischen Hintergrund finden Sie in den folgenden Beiträgen:
TechNet Blog: KeithMayer.com – Why R2? Step-by-Step: Automated Tiered Storage with Windows Server 2012 R2
TechNet Blog: Ask Premier Field Engineering (PFE) – Storage Spaces: How to configure Storage Tiers with Windows Server 2012 R2
Die Zusammenlegung von HDDs sowie SSDs führt zu der folgenden Situation: Mehrere große Festplatten, die nicht unbedingt schnell sind (z.B. 7.2k NL-SAS Festplatten mit 4 oder 6 TB) sorgen dafür, dass ausreichend Speicherplatz zur Verfügung steht. Mehrere SAS-SSDs sorgen dafür, dass der gesamte Pool ausreichend Performance bekommt.
Weiterer Vorteil bei der Nutzung von SSDs: Sie können einen Teil der SSDs als Write-Back Cache nutzen, ähnlich dem Cache auf einem RAID-Controller. Standardmäßig wird bei einem Storage Pool mit SSDs 1 GB an Speicherplatz für diese Caching-Technik genutzt. Aidan Finn hat zu diesem Thema einen Benchmark gemacht und auf seinem Blog veröffentlicht:
Aidan Finn – The Effects Of WS2012 R2 Storage Spaces Write-Back Cache
Bessere Performance-Werte um den Faktor 11 in einer (laut seiner Aussage) recht schnell aufgebauten Demo-Umgebung zeigen den unglaublichen Performanceschub bei Nutzung dieser Technik.
Lassen Sie den Standard-Wert von 1 GB auf diesem Wert stehen, dies ist laut Aussage der Produktgruppe ein optimaler Wert.
Die Vorbereitung der Server
Das Netzwerk
Nach der Grundinstallation und einem Update auf den aktuellsten Patchlevel beginnt die Einrichtung mit der Konfiguration der Netzwerkkarten. Es werden insgesamt drei Netze genutzt:
- Management – In diesem Netz befindet sich die Active Directory
- Storage1 – Eines der beiden SMB-Netze
- Storage2 – Das zweite SMB-Netz

In optimalen Fall besitzen die Server mindestens zwei Gbit-Adapter und vier 10 Gbit-Adapter. Dies ermöglicht die Nutzung von zwei Teams über beide 10 Gbit-Adapter. Dies ist notwendig, da SMB MultiChannel in einem Failover Cluster nur dann funktioniert, wenn sich alle Adapter in einem unterschiedlichen Subnetz befinden. Wenn wir davon ausgehen, dass die Hyper-V Hosts nur zwei Adapter im Storage-Netzwerk besitzen, können die SOFS-Knoten ebenfalls nur IP-Netze nutzen. Sollten die Hyper-V Hosts ebenfalls vier Adapter für SMB besitzen muss kein Team erstellt werden.
Die einzelnen Adapter werden in der Systemsteuerung umbenannt, um hier eine bessere Übersicht zu haben. Das Resultat sieht wie folgt aus:

Falls Sie mehrere Server konfigurieren möchten lässt sich diese Benennung per PowerShell ein wenig automatisieren:
Get-NetAdapter -InterfaceDescription “Intel(R) I350 Gigabit Network Connection” | Rename-NetAdapter -NewName 1GBit#1 –PassThru
Das Management-Netzwerk wird über Gbit-Karten abgebildet. Zur Redundanz werden hier zwei der vier onboard-Adapter zu einem Team zusammengeschlossen und konfiguriert. Dies kann entweder per GUI oder per PowerShell erfolgen:
New-NetLBFOTeam -Name “Management-Team” -TeamNICName “Management-Team” -TeamMembers 1GBit#1, 1GBit#2 -TeamingMode SwitchIndependent -LoadBalancingAlgorithm Dynamic -Confirm:$false

Danach werden die Karten mit IP-Adressen versehen. Das Resultat sieht wie folgt aus:
Management



Storage1



Storage2
Diese Karte hat bis auf die IP-Adresse die exakt gleichen Einstellungen wie Storage1 bzw. 10GBit#1. Diese Karte enthält die folgende IP-Adresse

Die Storage-Karten werden übrigens nicht geteamt, SMB3 ermöglicht eine Nutzung beider Adapter gleichzeitig (SMB Multichannel).
Die Konfiguration per PowerShell
Die oben gezeigte Konfiguration lässt sich komplett per PowerShell realisieren.
# Abfrage der IP-Adresse
$IP = Read-Host “Geben Sie das letzte Oktett der IP-Adresse eine”
# Team erstellen
New-NetLBFOTeam -Name “Management-Team” -TeamNICName “Management-Team” -TeamMembers `
1GBit#1, 1GBit#2 -TeamingMode SwitchIndependent -LoadBalancingAlgorithm Dynamic -Confirm:$false
# IP-Konfiguration
Set-NetIPInterface -InterfaceAlias “Management-Team” -dhcp Disabled -verbose
New-NetIPAddress -AddressFamily IPv4 -PrefixLength 24 -InterfaceAlias “Management-Team” `
-IPAddress 192.168.209.$IP -verbose
Set-DnsClientServerAddress -InterfaceAlias “Management-Team” -ServerAddresses 192.168.209.1
Set-NetIPInterface -InterfaceAlias “10GBit#1” -dhcp Disabled -verbose
New-NetIPAddress -AddressFamily IPv4 -PrefixLength 24 -InterfaceAlias “10GBit#1” `
-IPAddress 192.168.208.$IP -verbose
Set-DnsClientServerAddress -InterfaceAlias “10GBit#1” -ServerAddresses 192.168.209.1
Set-NetAdapterBinding -Name “10GBit#1” -ComponentID ms_tcpip6 -Enabled $False
Set-NetIPInterface -InterfaceAlias “10GBit#2” -dhcp Disabled -verbose
New-NetIPAddress -AddressFamily IPv4 -PrefixLength 24 -InterfaceAlias “10GBit#2” `
-IPAddress 192.168.207.$IP -verbose
Set-DnsClientServerAddress -InterfaceAlias “10GBit#2” -ServerAddresses 192.168.209.1
Set-NetAdapterBinding -Name “10GBit#2” -ComponentID ms_tcpip6 -Enabled $False
Nehmen Sie die Systeme nun in die Active Directory auf und vergeben Sie einen aussagekräftigen Namen. In unserem Fall heißen die Systeme FSNode1 und FSNode2.
Als letzten Punkt der Netzwerk-Konfiguration setzen wir auf den Systemen in den erweiterten Einstellungen innerhalb der Netzwerkverbindungen das Management-Team an die vorderste Stelle.


Die Installation der benötigten Rollen und Features
Auf den beiden Systemen werden die folgenden Rollen und Features benötigt


Der Dateiserver wird benötigt, da dieser später als Rolle im Failover Cluster installiert und eingerichtet wird. Um eine Sicherung der VM-Daten machen zu können wird ebenfalls der VSS Agent Service benötigt. Einen Schritt weiter bei den Features wird das Failover Cluster-Feature inkl. den Verwaltungstools sowie MPIO (Multipfad E/A im deutschen) benötigt. Die Installation per PowerShell sieht wie folgt aus:
Install-WindowsFeature -Name FS-Fileserver, FS-VSS-Agent, Failover-Clustering, `
Multipath-IO -IncludeManagementTools

Wenn der Parameter –Computername noch mit angegeben wird kann die Installation auch remote durchgeführt werden.

Falls Sie noch weitere Rollen oder Features benötigen, hier ein Befehl zur Auflistung aller vorhandenen Rollen und Features:
Get-WindowsFeature | Select-Object -ExpandProperty Name | Write-Host
Die Einrichtung von MPIO
Dieser Schritt muss nur gemacht werden, wenn HDDs bzw. SSDs in einem oder mehreren JBODs verwendet werden, die mit mehr als einem SAS-Kabel angeschlossen sind. In unserem Fall hat jeder Server zwei Verbindungen pro JBOD, daher muss auf unseren Servern MPIO aktiviert werden. Die Aktivierung kann entweder per GUI oder per PowerShell gemacht werden und bedingt einen Neustart, der nach der Bestätigung des Neustarts auch direkt gemacht wird.

Per PowerShell funktioniert es mit dem folgenden Befehl
Enable-MSDSMAutomaticClaim -BusType SAS
Ein Neustart wird an dieser Stelle nicht eingefordert, ist aber auf jeden Fall sinnvoll
Restart-Computer
Die Überprüfung der Disks
Wenn Sie mehrere HDDs bzw. SSDs nutzen, kann es zu unterschiedlichen Performance-Werten bei eigentlich gleichen Datenträgern kommen. Bei einem Scale-Out File Server kann es zu sehr starken Einschränkungen bei der Gesamtperformance kommen, wenn ein oder mehrere Datenträger langsamer arbeiten wie andere. Aus diesem Grund sollten Sie vor der Nutzung Ihrer HDDs und SSDs einen Test machen, der Ihnen die Performance aller Datenträger ermittelt und aufführt. Sie benötigen ein PowerShell-Skript und die aktuellste Version des SQLIO-Tools:
Technet Script Center: Storage Spaces Physical Disk Validation Script
Microsoft Download Center: SQLIO Disk Subsystem Benchmark Tool
Technet Script Center: Completely Clearing an Existing Storage Spaces Configuration
Falls die HDDs oder SSDs bereits für etwas genutzt wurden benötigen Sie das unterste Skript zur kompletten Entfernung aller Informationen auf den Datenträgern. Achten Sie darauf, dass mit diesem Skript die Datenträger gelöscht werden. Falls Sie Daten auf den Disks noch benötigen, fertigen Sie ein Backup an!
Führen Sie das Skript aus und warten Sie darauf, dass alle Datenträger gelöscht wurden

Installieren Sie SQLIO auf dem Server und kopieren Sie die sqlio.exe-Datei an den Standort, an dem das Validation-Skript liegt. Alternativ kopieren Sie das Skript in das Installationsverzeichnis.

Führen Sie den folgenden Befehl aus und überprüfen Sie, ob die korrekten Datenträger aufgeführt werden
Get-PhysicalDisk |? {($_.CanPool) -and (!$_.IsPartial)}

Speichern Sie nun diese Datenträger in der Variablen $physicaldisks_to_pool mit dem Befehl
$physicaldisks_to_pool = Get-PhysicalDisk |? {($_.CanPool) -and (!$_.IsPartial)}
Starten Sie nun den Test mit dem folgenden Befehl
.\Validate-StoragePool.ps1 -PhysicalDisks $physicaldisks_to_pool

Der Test beginnt und listet Ihnen auf, wie viele HDDs und SSDs vorhanden sind. In meinem Fall sind es fünf SSDs und 19 HDDs. Der Test läuft nun einige Stunden, daher empfiehlt es sich diesen zu einem Zeitpunkt zu starten, an dem noch andere Aufgaben erledigt werden müssen oder der Feierabend winkt.
Als Ausgabe nach dem erfolgreichen Test erscheint der folgende Bericht

Schauen Sie sich die Warnungen und ggf. Fehler an, um potentiell schlechte Datenträger auszutauschen. In meinem Fall werden vier Datenträger bei der Leselatenz sowie drei Datenträger bei der Schreiblatenz angemerkt. Die ersten Werte liegen mit 830, 768, 776 und 801 ms nur wenig über dem Durchschnittswert von 620, bei den Schreiblatenzen könnte PhysikalDisk19 mit einer maximalen Latenz von knapp unter dem doppelten des Durchschnitts (1008 ms bei durchschnittlich 634 ms) evtl. getauscht werden. Führen Sie den Test evtl. ein zweites Mal durch und vergleichen Sie die Ergebnisse, um zufällige hohe Latenzen auszumerzen.
Die Erstellung des Failover Cluster
Wir sind nun an der Stelle angelangt, an dem das Failover Cluster erstellt und konfiguriert werden kann. Öffnen Sie dazu den Failover Cluster Manager und wählen Sie den Punkt Konfiguration überprüfen bzw. Validate Configuration….

Wählen Sie die beiden Server aus, die Mitglied des Failover Cluster werden sollen und führen Sie alle Tests aus.

Der Test versucht nun, alle Festplatten an allen Knoten zu erreichen. Sollte es hier zu Problemen kommen, wird Ihnen dies an dieser Stelle direkt angemerkt, nicht erst zu einem späteren Zeitpunkt während der Erstellung bzw. Konfiguration.

Sie können diesen Test natürlich auch per PowerShell starten, der Befehl hierzu lautet
Test-Cluster -Node FSNode1,FSNode2
Sie können jederzeit sehen, an welchem Punkt der Test sich gerade befindet

Nach Beendigung sehen Sie ein Ergebnis sowie den Pfad zu dem kompletten Bericht des Tests.

Schauen Sie sich diesen Test unbedingt an und korrigieren Sie potentielle Fehler. Sie können auch mit dem Parameter –ReportName einen Namen und einen Speicherort für den Bericht angeben, das macht die Suche einfacher.

Nachdem die Konfiguration nun überprüft wurde können Sie den Failover Cluster erstellen. Beenden Sie dazu den Überprüfungs-Assistenten und wechseln Sie in den Cluster erstellen-Assistenten. Fügen Sie die beiden Knoten hinzu

und wählen Sie einen Namen und eine IP-Adresse für das Failover Cluster. Da ich in meinem Fall kein Gateway gesetzt habe werde ich für alle Netze nach einer Adresse gefragt. An dieser Stelle deaktiviere ich alle Netze bis auf das Management-Netzwerk und setze nur in diesem Netzwerk eine IP-Adresse.

Achten Sie im nächsten Schritt unbedingt darauf, dass Sie den gesamten verfügbaren Speicher nicht automatisch hinzufügen lassen!

Nach einem Klick auf Weiter wird das Failover Cluster erstellt. Die Alternative per PowerShell wäre
New-Cluster –Name FSCluster1 –Node FSNode1,FSNode2 –StaticAddress `
192.168.209.110 -IgnoreNetwork 192.168.207.0/24,192.168.208.0/24 –NoStorage

Nach der Erstellung können Sie das Failover Cluster über den Failover Cluster Manager administrieren und benutzen.

Die Konfiguration des Failover Cluster zur Nutzung als Scale-Out File Server
Nach der Erstellung müssen noch ein paar Einstellungen angepasst werden, bevor die Erstellung des hochverfügbaren Dateiservers beginnen kann.
Das Netzwerk
Die Netzwerke sind aktuell in einer recht unsagenden Reihenfolge benannt, dies möchten wir gerne ändern und sprechende Namen verwenden. Wechseln Sie im linken Menü auf Netzwerk und setzen Sie die Namen der Netzwerke so, wie sie auch auf den lokalen Hosts konfiguriert sind.

Per Hand geht dies über die Eigenschaften der einzelnen Netzwerke, per PowerShell mit den folgenden drei Zeilen
(Get-ClusterNetwork | where-object {$_.Address -eq “192.168.209.0”}).Name = “Management”
(Get-ClusterNetwork | where-object {$_.Address -eq “192.168.208.0”}).Name = “Storage1”
(Get-ClusterNetwork | where-object {$_.Address -eq “192.168.207.0”}).Name = “Storage2”
Nach der Umbenennung sehen die Netzwerke wie folgt aus

Neben dem Netzwerk sollte noch die Metrik der einzelnen Karten überprüft werden. Dies geht ausschließlich per PowerShell
Get-ClusterNetwork | ft Name, Metric, AutoMetric -AutoSize

In meinem Fall hat Storage2 die kleinste Metric, dies bedeutet diese Karte hat im Failover Cluster die höchste Priorität (Je kleiner die Metric, desto höher die Priorität; allerdings immer abhängig von den anderen Karten). Die hier automatisch gesetzten Werte sind in Ordnung, falls diese geändert werden sollen geht dies mit den folgenden Befehlen
(Get-ClusterNetwork “Management”).Metric = 200
(Get-ClusterNetwork “Storage1”).Metric = 100
(Get-ClusterNetwork “Storage2”).Metric = 101
In diesem Beispiel wird Storage1 die Karten mit der höchsten Priorität, gefolgt von Storage2.
Ein Livemigration-Netzwerk müssen wir in dieser Art von Failover Cluster nicht aktiv konfigurieren, da keine VMs betrieben werden und somit auch kein RAM übertragen werden muss.
Zur Nutzung der beiden Storage-Karten für den Dateiserver später muss die Nutzung im Cluster umgestellt werden. Aktuell stehen die Netzwerke auf “Cluster only”, dies muss korrigiert werden auf “Cluster and Client”, da sonst kein Zugriff auf die Freigaben über diese Karten möglich ist. Setzen Sie die Option über die Gui

oder per PowerShell:
(Get-ClusterNetwork “Storage1”).Role = 3
(Get-ClusterNetwork “Storage2”).Role = 3
Die Rolle 1 bedeutet “Nur Cluster”, 3 bedeutet “Cluster und Client”.
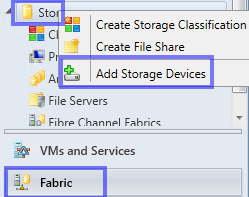
Der Datenträgerpool
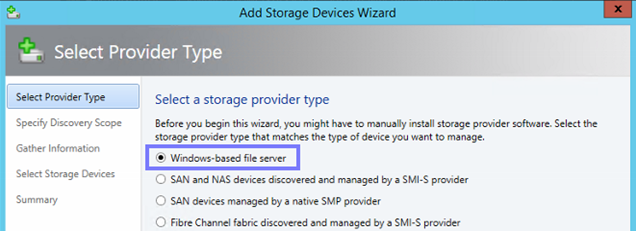
Um mit den Datenträgern in unserem JBOD arbeiten zu können wird ein Pool benötigt. Dieser Pool enthält alle HDDs und SSDs, die Erstellung kann per GUI oder per PowerShell vorgenommen werden.
Im Failover Cluster Manager wechseln Sie unter Speicher auf Pools und erstellen mit dem Menüpunkt Neuer Storage Pool eine neue Ansammlung von Datenträgern.

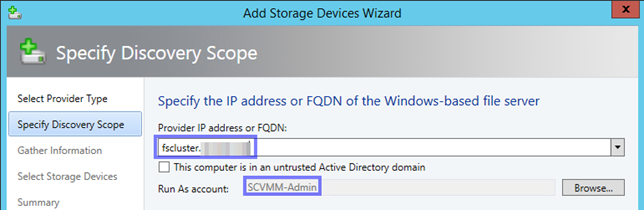
Im nächsten Schritt können Sie die Datenträger wählen, die Mitglied des Pools werden sollen. Sie sehen hier bereits die Größe, den Steckplatz, den Typ und weitere Informationen.

Unter Zuordnung bzw. Allocation belassen Sie alle Datenträger auf Automatisch, außer Sie wollen an dieser Stelle eine oder mehrere HotSpare-Datenträger definieren. Nach einem Klick auf Weiter sehen Sie eine Zusammenfassung, danach kann die Erstellung beginnen.

Per PowerShell können Sie den Pool wie folgt einrichten:
Suchen Sie im ersten Schritt nach allen verfügbaren Datenträgern
Get-PhysicalDisk | ft FriendlyName, CanPool, PhysicalLocation –AutoSize
Dieser Befehl listet Ihnen alle physischen Datenträger auf und zeigt Ihnen sowohl die Fähigkeit, einem Pool beizutreten als auch den Ort, an dem der Datenträger verbunden ist. In meinem Fall sehen wir auf dem System insgesamt 26 Datenträger, wovon 24 in meinem JBOD stecken

Datenträger 0 und 25 haben keine Informationen über den Aufenthaltsort, bei den anderen 24 Datenträgern erkennt man das JBOD. Mit der folgenden Zeile können Sie alle Festplatten zum Pool hinzufügen, achten Sie aber darauf die Seriennummer an Ihre eigene PhysicalLocation anzupassen.
New-StoragePool -FriendlyName Pool01 -StorageSubSystemFriendlyName *Spaces* `
-PhysicalDisks (Get-PhysicalDisk | where PhysicalLocation -like *500093D001CEC000*)
Falls mehrere JBODs eingesetzt werden, sollte an dieser Stelle die Enclosure Awareness eingeschaltet werden. Dies geht ausschließlich per PowerShell und wird mit dem folgenden Befehl erreicht:
Get-StoragePool -FriendlyName Pool01 | Set-StoragePool -EnclosureAwareDefault $true
Überprüfen können Sie den Wert mit dem folgenden Befehl:
Get-StoragePool -FriendlyName Pool01 | ft FriendlyName, EnclosureAwareDefault -AutoSize
Nun haben wir einen Pool, der im nächsten Schritt als Grundlage für unsere virtuellen Datenträger genutzt werden kann.
Die Erstellung der virtuellen Datenträger
Bei der Erstellung der Datenträger sollten Sie (wie bereits in den Vorbemerkungen weiter oben angesprochen) darauf achten, dass Sie ausreichend Platz lassen, damit der Rebuild bei einem Ausfall schnell funktionieren kann. Ich nutze in diesem Aufbau insgesamt 24 Datenträger, wovon fünf SSDs mit jeweils 200 GB und 19 HDDs mit jeweils 1 TB Speicherplatz sind.

Rein theoretisch habe ich nun die folgenden Werte in meinem Scale-Out File Server:
- Anzahl JBODs: 1
- Coloums: 5, da insgesamt fünf SSDs vorhanden sind
- Freier HDD-Speicherplatz: ((19TB/19+ 8GB) * 1 = 1,008 TB
- Freier SSD-Speicherplatz: ((1000GB/5) + 8GB) * 1 = 208 GB
Wir erinnern uns, die Formel zur Berechnung ist
((Freier Speicherplatz/Anzahl der Datenträger) + 8GB) * Anzahl der Enclosure
Da wir ja alle seit der Erfindung von calc.exe eher weniger im Kopf rechnen möchten hier ein kleines Skript, welches die genaue Anzahl des freien Speicherplatz ausrechnet und in entsprechender Form ausgibt:
# j.kappen@rachfahl.de, 23.04.2014, Kalkulation des freien Speicherplatzes in einem StoragePool
# Ausgabe der vorhandenen Pools
Get-StoragePool
Write-Host “”
Write-Host “”
# Abfrage der Enclosure und des Pool-Namen
$anzahlenclosure = Read-Host “Geben Sie die Anzahl der Enclosure an”
$poolname = Read-Host “Geben Sie den Namen des Pools an, bei dem die Groessen berechnet werden sollen”
# Berechnung des SSD-Speichers
$disks = Get-StoragePool -FriendlyName $poolname | Get-PhysicalDisk | where MediaType -eq SSD
$ssdSpace = 0
$ssddiskCount = 0
foreach ($disk in $disks)
{
if ($disk.MediaType -eq “SSD”)
{
$ssdSpace += $disk.Size
$ssddiskCount++
}
}
# Berechnung des HDD-Speichers
$disks = Get-StoragePool -FriendlyName $poolname | Get-PhysicalDisk | where MediaType -eq HDD
$hddSpace = 0
$hdddiskCount = 0
foreach ($disk in $disks)
{
if ($disk.MediaType -eq “HDD”)
{
$hddSpace += $disk.Size
$hdddiskCount++
}
}
#Berechnung
$ssdSpaceinGB = $ssdSpace / 1024 / 1024 / 1024
$hddSpaceinGB = $hddSpace / 1024 / 1024 / 1024
$hddSpaceinTB = $hddSpace / 1024 / 1024 / 1024 / 1024
# ((Freier Speicherplatz/Anzahl der Datenträger) + 8GB) * Anzahl der Enclosure
$freessdspace = (($ssdSpaceinGB / $ssddiskCount) + 8GB) * $anzahlenclosure
$freehddspace = (($hddSpaceinGB / $hdddiskCount) + 8GB) * $anzahlenclosure
# Ausgabe der Ergebnisse
Write-Host -ForegroundColor Green “Kalkulation der empfohlenen Groessen”
Write-Host -ForegroundColor Green “————————————–”
Write-Host -ForegroundColor Green “Anzahl der SSDs:” $ssddiskCount
Write-Host -ForegroundColor Green “Gesamter SSD-Speicherplatz”
Write-Host -ForegroundColor Green “————————————–”
Write-Host -ForegroundColor Green $ssdSpace “Byte =>” $ssdSpaceinGB “GB”
Write-Host “”
Write-Host -ForegroundColor Green “————————————–”
Write-Host -ForegroundColor Green “Freier benoetigter SSD-Speicherplatz”
Write-Host -ForegroundColor Green $freessdspace “GB”
Write-Host “”
Write-Host “”
Write-Host -ForegroundColor Green “————————————–”
Write-Host -ForegroundColor Green “Anzahl der HDDs:” $hdddiskCount
Write-Host -ForegroundColor Green “Gesamter HDD-Speicherplatz”
Write-Host -ForegroundColor Green “————————————–”
Write-Host -ForegroundColor Green $hddSpace “Byte =>” $hddSpaceinGB “GB =>” $hddSpaceinTB “TB”
Write-Host “”
Write-Host -ForegroundColor Green “————————————–”
Write-Host -ForegroundColor Green “Freier benoetigter HDD-Speicherplatz”
Write-Host -ForegroundColor Green $freehddspace “GB”
Download: Berechnung_Freier_Speicherplatz_SOFS.txt
Das Skript fragt die Anzahl der Enclosure und den Namen des Pools ab und errechnet danach sowohl für SSDs als auch für HDDs den freien Speicherplatz.

Da wir nun den Speicherplatz ausgerechnet haben können wir mit der Erstellung der Datenträger fortfahren. Dies geht entweder per Failover Cluster Manager oder per PowerShell. Die GUI erlaubt ziemlich wenig Anpassungen gegenüber den Standardwerten, der wichtigste Punkt ist die Konfiguration der Blockgröße / des Interleave. Aus diesem Grund nehme ich die komplette Erstellung innerhalb der PowerShell vor.
Bei der Anzahl der Datenträger benötigen wir mindestens so viele Datenträger wie Cluster Knoten, in meinem Fall zwei. Zusätzlich kommt noch ein Quorum-Datenträger hinzu mit einer Größe von fünf GB. Dieser wird seit Server 2012 R2 immer benötigt, da immer ein Quorum zugewiesen wird und das Failover Cluster dynamisch mit dem Quorum arbeitet oder nicht, je nach Anzahl der Knoten. Da wir in diesem Aufbau zwei Server haben wir sowieso ein Quorum benötigt.
Die Erstellung des Quorum
Zur Erstellung des Quorum wird der folgende Befehl verwendet
Get-StoragePool Pool01 | New-VirtualDisk -FriendlyName “FSQuorum” -ResiliencySettingName “Mirror” -NumberOfDataCopies 3 -Size 5GB -Interleave 64KB
Dies bewirkt, dass im Storage Pool Pool01 ein neuer Datenträger mit dem Namen FSQuorum angelegt wird. Die Datensicherheit (Resiliency) ist ein Spiegel (Mirror), die Anzahl der Kopien sind 3 (d.h. es ist ein Drei-Wege-Spiegel). Die Größe wird mit 5 GB angegeben und die Interleave-Größe beträgt 64KB. Nach der Erstellung sieht der Datenträger im Failover Cluster Manager bzw. in der PowerShell wie folgt aus


Man erkennt, dass der Datenträger 8 GB groß geworden ist, trotz dem Befehl mit 5 GB. Dies liegt vermutlich an der Aufteilung der Daten auf den unterschiedlichen Festplatten, 8 GB scheint in diesem Fall die kleinste Größe zu sein. Bei knapp 20 TB an Speicherplatz ist dies aber nicht weiter tragisch.
Da ich bei der Erstellung nichts von einem Tiering angegeben habe, wurde dieser Datenträger komplett auf HDDs angelegt. Dies ist nicht weiter schlimm, auf dem Quorum-Datenträger wird sehr wenig geschrieben und gelesen, daher ist hier Tiering absolut nicht notwendig.
Damit ich das Laufwerk nutzen kann muss es nun noch formatiert werden. Dies geht entweder manuell über den Failover Cluster Manager (und auch nur, wenn der Wartungsmodus für den Datenträger aktiviert ist) oder ebenfalls per PowerShell. Achten Sie bei der Formatierung per GUI darauf, dass der Datenträger auf dem Host liegt, auf dem Sie die Formatierung machen möchten. In meinem Fall ist dies FSNode1.
# Datenträger auflisten
Get-VirtualDisk
Write-Host “”
Write-Host -ForegroundColor Red “Achtung, diese Aktion formatiert einen oder mehrere Datenträger!”
Write-Host “”
# Name abfragen
$vdName = Read-Host “Geben Sie einen Namen des Datenträger an, den Sie formatieren möchten”
# Lokalen Computernamen herausfinden und speichern
$ComputerName = $env:COMPUTERNAME
# Neuen, verfügbaren Datenträger auf den lokalen Knoten verschieben
Move-ClusterGroup “Available Storage” –Node $ComputerName
# Cluster-Ressourcen auflisten und einlesen
$clusterResource = Get-ClusterResource | where Name -like *$vdName*
# Wartungsmodus aktivieren
Suspend-ClusterResource $clusterResource
# Datenträger formatieren
Get-VirtualDisk $vdName | Get-Disk | New-Partition –UseMaximumSize | Format-Volume `
–FileSystem NTFS –AllocationUnitSize 64KB –NewFileSystemLabel $vdName –Confirm:$false
#unset VirtualDisk Maintance Mode
Resume-ClusterResource $clusterResource
Download: Formatierung_Datentraeger_FailoverCluster.txt

Nach der Formatierung sieht der Datenträger im Failover Cluster Manager wie folgt aus

Die Erstellung der weiteren CSV-Datenträger
Im zweiten Schritt werden nun die CSV-Datenträger erstellt, in denen letztendlich die Daten der VMs gespeichert werden. Ich habe zwei Server, daher erstelle ich zwei virtuelle Datenträger. Um die korrekte Größe inkl. dem bereits erstellten Quorum zu setzen, hier ein weiteres Skript, welches auf die Daten aufbaut, die das vorherige Skript ausgeworfen hat.
$gesamtHDDSpace = Read-Host “Geben sie die gesamte HDD-Größe in GB ein”
$gesamtSSDSpace = Read-Host “Geben sie die gesamte SSD-Größe in GB ein”
$freierHDDSpace = Read-Host “Geben sie Reserve-Speicherplatz der HDDs in GB ein”
$freierSSDSpace = Read-Host “Geben sie Reserve-Speicherplatz der SSDs in GB ein”
$mirrorlevel = Read-Host “Geben Sie den Spiegel an, den Sie nutzen möchten (2 oder 3)”
$anzahlvdisks = Read-Host “Geben Sie die Anzahl der CSV-Datenträger ein”
Write-Host “”
$hddcsvsize = ($gesamtHDDSpace – $freierHDDSpace) / $mirrorlevel / $anzahlvdisks
$ssdcsvsize = ($gesamtSSDSpace – $freierSSDSpace) / $mirrorlevel / $anzahlvdisks
Write-Host -ForegroundColor Green “Größe des SSD-Speicherplatz:” $ssdcsvsize
Write-Host -ForegroundColor Green “Größe des HDD-Speicherplatz:” $hddcsvsize

Zur Erstellung werden die folgenden Zeilen Code genutzt:
# Storage-Tiers entfernen
Get-StorageTier | Remove-StorageTier
# Definiton
$poolName = “Pool01”
$ssdTierName = “SSD-Tier”+ $poolName
$hddTierName = “HDD-Tier”+ $poolName
$dataCopies = 3
$columnCount = 1
New-StorageTier -StoragePoolFriendlyName $poolName `
-FriendlyName $ssdTierName -MediaType SSD
New-StorageTier -StoragePoolFriendlyName $poolName `
-FriendlyName $hddTierName -MediaType HDD
$ssd_tier = Get-StorageTier | where FriendlyName -eq $ssdTierName
$hdd_tier = Get-StorageTier | where FriendlyName -eq $hddTierName
$ssdTierSize = 122GB
$hddTierSize = 2791GB
# Erstellung der Datenträger
New-VirtualDisk -StoragePoolFriendlyName $poolName `
-StorageTiers @($ssd_tier,$hdd_tier) `
-StorageTierSizes $ssdTierSize,$hddTierSize `
-ResiliencySettingName Mirror -NumberOfDataCopies $dataCopies `
-NumberOfColumns $columnCount -ProvisioningType Fixed `
-FriendlyName vDisk1 -Interleave 64KB -IsEnclosureAware:$true
New-VirtualDisk -StoragePoolFriendlyName $poolName `
-StorageTiers @($ssd_tier,$hdd_tier) `
-StorageTierSizes @($ssdTierSize,$hddTierSize) `
-ResiliencySettingName Mirror -NumberOfDataCopies $dataCopies `
-NumberOfColumns $columnCount -ProvisioningType Fixed `
-FriendlyName vDisk2 -Interleave 64KB -IsEnclosureAware:$true
Auf Wunsch können diese Datenträger nun auch noch per PowerShell formatiert werden. Hierzu wird das gleiche Verfahren wie bei dem Quorum-Datenträger genutzt.
# Datenträger auflisten
Get-VirtualDisk
Write-Host “”
Write-Host -ForegroundColor Red “Achtung, diese Aktion formatiert einen oder mehrere Datenträger!”
Write-Host “”
# Name abfragen
$vdName = Read-Host “Geben Sie einen Namen des Datenträger an, den Sie formatieren möchten”
# Lokalen Computernamen herausfinden und speichern
$ComputerName = $env:COMPUTERNAME
# Neuen, verfügbaren Datenträger auf den lokalen Knoten verschieben
Move-ClusterGroup “Available Storage” –Node $ComputerName
# Cluster-Ressourcen auflisten und einlesen
$clusterResource = Get-ClusterResource | where Name -like *$vdName*
# Wartungsmodus aktivieren
Suspend-ClusterResource $clusterResource
# Datenträger formatieren
Get-VirtualDisk $vdName | Get-Disk | New-Partition –UseMaximumSize | Format-Volume –FileSystem `
NTFS –AllocationUnitSize 64KB –NewFileSystemLabel $vdName –Confirm:$false
#unset VirtualDisk Maintance Mode
Resume-ClusterResource $clusterResource

Nun sind zwei neue Datenträger vorhanden, jeweils mit einer Größe von 2,84 TB. Die Formatierung ist ebenfalls gemacht worden, die Blockgröße von 64KB wurde hierbei beachtet. In meinem Fall kann ich nur eine Coloum-Zahl von 1 verwenden, da fünf SSDs durch drei 1,66 sind. Alles nach dem Komma zählt nicht, die Coloum-Zahl beträgt 1. Um auf 2 zu kommen würde noch eine weitere SSD benötigt, für jede weitere Zahl drei weitere SSDs.

Damit diese Datenträger später als Speicher des Scale-Out File Server genutzt werden können müssen sie zu den Cluster Shared Volumes hinzugefügt werden. Dies geschieht entweder über den entsprechenden Punkt im Kontext-Menü oder per PowerShell:
Get-VirtualDisk
Write-Host “”
$vdName = Read-Host “Geben Sie den Namen des Datenträgers ein, der als CSV-Datenträger konfiguriert werden soll”
$clusterResource = Get-ClusterResource -Name “*$vdName*”
Add-ClusterSharedVolume -InputObject $clusterResource

Die Konfiguration der Quorum-Einstellungen
Als nächstes muss der 8 GB große Datenträger als Quorum-Datenträger konfiguriert werden. Dies geht über den Failover Cluster Manager über die erweiterten Befehle und dem Punkt Clusterquorumeinstellungen konfigurieren





Die Alternative per PowerShell:
Set-ClusterQuorum -NodeAndDiskMajority “Cluster Virtual Disk (FSQuorum)”

Mit diesem Schritt ist die Konfiguration schon beendet.
Die Erstellung und Konfiguration der Dateiserver-Rolle
Im nächsten Schritt müssen wir die Dateiserver-Rolle installieren und einrichten. Per GUI wird dies über Rollen – Rolle konfigurieren gemacht.

Wählen Sie den Dateiserver aus und bestätigen Sie die Auswahl mit Weiter.

Der nächste Schritt ist der wichtigste, an dieser Stelle wird die Art des Dateiserver ausgewählt. Der obere Punkt ist ein gewöhnlicher Dateiserver, der für die Ablage von Dateien genutzt werden kann. Dies wird in unserem Fall nicht benötigt, wir benötigen die untere Art von Dateiserver (im englischen als Scale-Out File Server bezeichnet, im deutschen als Dateiserver mit horizontaler Skalierung).

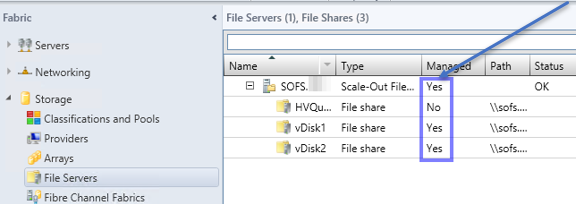
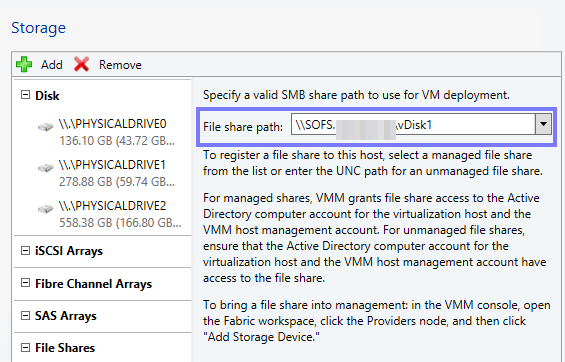
Unter Clientzugriffspunkt müssen Sie einen Namen für den Dateiserver eingeben. Unter diesem Namen ist der Server im Netzwerk erreichbar und ansprechbar. In meinem Fall nenne ich den Zugriffspunkt SOFS, d.h. mein Scale-Out File Server ist im Netzwerk unter \\SOFS\Share1 erreichbar.

Nach einer Überprüfung der AD auf ein evtl. schon vorhandenes Objekt mit diesem Namen bekommen Sie eine Zusammenfassung der Einstellungen, Sie sehen hier direkt die drei Subnetze, die von der Rolle genutzt werden.

Nach einem Klick auf Weiter beginnt die Erstellung der Rolle. Die Installation per PowerShell kann mit dem folgenden Befehl durchgeführt werden:
Add-ClusterScaleOutFileServerRole -Name “SOFS”


Als nächster Schritt kommt nun die Erstellung mehrerer Freigaben, auf die unsere Hyper-V Hosts zugreifen können. Wählen Sie im Kontextmenü der Dateiserver-Rolle den Punkt Freigabe hinzufügen.

Wenn Sie die folgende Meldung erhalten

haben Sie zwei Möglichkeiten. Entweder Sie holen sich jetzt einen Kaffee und versuchen es später erneut, oder Sie verschieben die Dateiserver-Rolle auf den Host, auf dem Sie gerade angemeldet sind. Falls dies immer noch nichts bringt und Ihr Failover Cluster-Manager Fehler bringt, die ein Berechtigungsproblem in Ihrem DNS anmerken (dies war bei mir der Fall, da die Objekte im DNS bereits vorhanden waren und nicht überschrieben werden konnten), gehen Sie wie folgt vor: Löschen Sie im DNS alle Einträge mit dem Namen des Scale-Out File Server. Erstellen Sie danach ein neues Objekt mit dem Namen und einer IP. Fügen Sie danach in den Sicherheitseinstellungen des DNS-Objekt das Computerobjekt hinzu und geben Sie ihm die Rechte zur Änderung des Eintrags:

Bestätigen Sie die Einstellungen und verschieben Sie die Dateiserver-Rolle erneut. Nun sollten keine Fehler mehr auftauchen und die Erstellung einer neuen Freigabe sollte ebenfalls funktionieren. Weiterhin werden alle IPs im DNS unter dem Namen der Rolle angelegt.
Es öffnet sich ein Assistent, der Sie durch die Erstellung der Freigabe führt. Als erstes müssen Sie ein Profil auswählen, um welche Art von Freigabe es sich handelt. Da wir VMs speichern möchten sollte das Profil Anwendungen gewählt werden

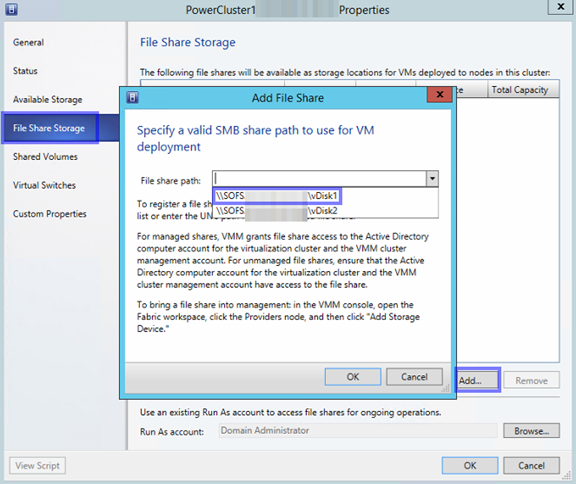
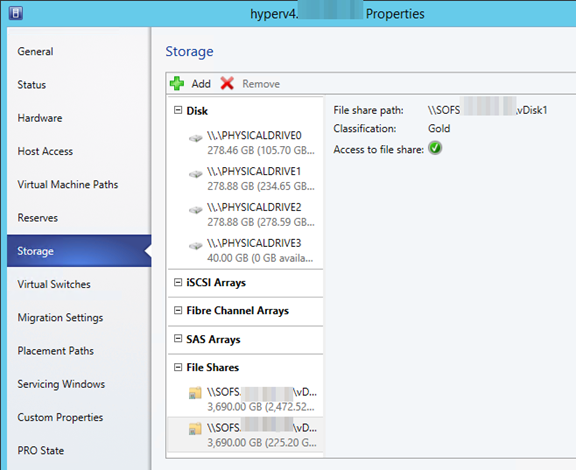
Im nächsten Schritt können Sie den Server wählen, hier ist direkt unsere Dateiserver-Rolle angewählt. im mittleren Bereich können Sie sehen, dass Sie hier nur die beiden CSVs auswählen können, keinen lokalen Pfad. Wir beginnen mit Volume1 und fahren im Assistenten fort.

Vergeben Sie nun einen Namen für die Freigabe. Ich habe sie in meinem Fall Share1 genannt. Sie können erkennen, wie sich der Name im unteren Bereich einträgt. An dieser Stelle können Sie bereits den kompletten Pfad sehen, über den Sie später Ihre VMs speichern.

Nach einem Klick auf Weiter sehen Sie, dass die erhöhte Verfügbarkeit eingeschaltet ist und auch nicht entfernt werden kann. Diese Option ermöglicht einen nahtlosen Betrieb der VMs, auch bei einem Ausfall oder einem Neustart eines der Datei Server-Knoten

Nun kommen wir zu einer sehr wichtigen Stelle: Die Konfiguration der Berechtigungen für diese Freigabe

Passen Sie diese Einstellungen wie folgt an: Wählen Sie Berechtigungen anpassen im unteren Bereich und deaktivieren Sie als erstes die Vererbung. Danach entfernen Sie die Benutzer-Berechtigungen auf dieser Freigabe, Benutzer haben an dieser Stelle nichts zu suchen. Fügen Sie danach die Computerkonten aller Hyper-V Hosts hinzu, die auf diese Freigabe zugreifen sollen. Zusätzlich fügen Sie das bzw. die Cluster-Objekte hinzu der Hyper-V Failover Cluster (falls Sie einen oder mehrere Hyper-V Failover Cluster betreiben). Zuletzt geben Sie den AD-Admins noch eine Berechtigung auf diese Freigabe.

Das Ergebnis sieht wie folgt aus


Nach einem Klick auf Weiter bekommen Sie eine kurze Zusammenfassung der Einstellungen, wenn diese korrekt sind können Sie die Freigabe erstellen.

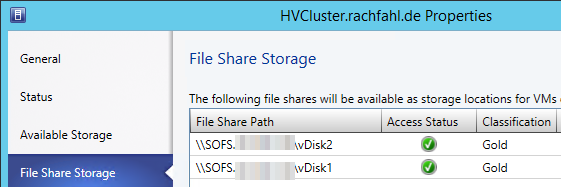
Erstellen Sie eine zweite Freigabe, die auf dem Volume2 erstellt wird. Die Einstellungen bleiben die gleichen, nur der Name ändert sich. Das Resultat sieht wie folgt aus

Die Einrichtung per PowerShell sieht wie folgt aus:
# Konfiguration_NTFS_Berechtigungen.ps1 – Jan Kappen – j.kappen@rachfahl.de
# Erstellung einer neuen Freigabe für die SOFS-Rolle und Anpassung
# der Rechte. Eine Anpassung ist notwendig an den markierten Stellen
#
# Konfiguration des Namen
# Anpassung notwendig!
$Sharename = “Share6”
$Volumename = “Volume1”
# Erstellen des neuen Ordners
New-Item -Name $Sharename -ItemType Directory
mkdir C:\ClusterStorage\$Volumename\Shares\$Sharename
# Erstellung eines neuen Shares mit HA und ohne Caching
#
# Falls die Quorum-Freigabe erstellt werden soll, kann der Parameter
# -ContiniousAvailable auf $false angepasst werden
#
New-SmbShare -Name $Sharename -Path C:\ClusterStorage\$Volumename\Shares\$Sharename `
-CachingMode None -FullAccess “everyone” -ContinuouslyAvailable $true
# Anzeige der Berechtigungen
Get-Acl “C:\ClusterStorage\$Volumename\Shares\$Sharename” | fl
# Benutzer aus den Rechten entfernen
$colRights = [System.Security.AccessControl.FileSystemRights]”Read”
$InheritanceFlag = [System.Security.AccessControl.InheritanceFlags]::None
$PropagationFlag = [System.Security.AccessControl.PropagationFlags]::None
$objType =[System.Security.AccessControl.AccessControlType]::Allow
$objUser = New-Object System.Security.Principal.NTAccount(“BUILTIN\Users”)
$objACE = New-Object System.Security.AccessControl.FileSystemAccessRule `
($objUser, $colRights, $InheritanceFlag, $PropagationFlag, $objType)
$objACL = Get-ACL “C:\ClusterStorage\$Volumename\Shares\$Sharename”
$objACL.RemoveAccessRuleAll($objACE)
Set-ACL “C:\ClusterStorage\$Volumename\Shares\$Sharename” $objACL
# Anzeige der Berechtigungen
Get-Acl “C:\ClusterStorage\$Volumename\Shares\$Sharename” | fl
# Besitzer konfigurieren
$acl = Get-Acl “C:\ClusterStorage\$Volumename\Shares\$Sharename”
$acl.SetOwner([System.Security.Principal.NTAccount] “Administrators”)
Set-Acl C:\ClusterStorage\$Volumename\Shares\$Sharename $acl
#
$acl = Get-Acl C:\ClusterStorage\$Volumename\Shares\$Sharename
$acl.SetAccessRuleProtection($True, $False)
#
# Anpassung der Systemnamen sowie des Failover Cluster-Objekts notwendig!
#
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule `
(“Powerkurs\Hyperv14$”,”FullControl”, “ContainerInherit, ObjectInherit”, “None”, “Allow”)
$acl.AddAccessRule($rule)
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule `
(“Powerkurs\Hyperv15$”,”FullControl”, “ContainerInherit, ObjectInherit”, “None”, “Allow”)
$acl.AddAccessRule($rule)
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule `
(“Powerkurs\powercluster1$”,”FullControl”, “ContainerInherit, ObjectInherit”, “None”, “Allow”)
$acl.AddAccessRule($rule)
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule `
(“Powerkurs\domain admins”,”FullControl”, “ContainerInherit, ObjectInherit”, “None”, “Allow”)
$acl.AddAccessRule($rule)
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule `
(“SYSTEM”,”FullControl”, “ContainerInherit, ObjectInherit”, “None”, “Allow”)
$acl.AddAccessRule($rule)
$rule = New-Object System.Security.AccessControl.FileSystemAccessRule `
(“CREATOR OWNER”,”FullControl”, “ContainerInherit, ObjectInherit”, “None”, “Allow”)
$acl.AddAccessRule($rule)
Set-Acl C:\ClusterStorage\$Volumename\Shares\$Sharename $acl
# Erneute Anzeige der Einstellungen
Get-Acl C:\ClusterStorage\$Volumename\Shares\$Sharename | Format-List
Download: PowerShell Skript: Konfiguration_NTFS_Berechtigungen

Die Erstellung einer Freigabe zur Nutzung als Quorum
An dieser Stelle müssen wir noch eine weitere Freigabe erstellen, die als Quorum für unser Hyper-V Failover Cluster genutzt wird. Bei dieser Freigabe gibt es eine kleine Besonderheit: Sie sollte nicht dauerhaft zur Verfügung stehen, heißt wir konfigurieren diese Freigabe ein wenig anders. Diese Konfiguration kann allerdings erst nach der Erstellung gemacht werden, die Erstellung ist gleich wie bei den beiden Shares oben. In welchem Volume Sie die Freigabe erstellen ist grundsätzlich egal, ich lege sie in meinem Fall auf Volume1.
Nach der Erstellung sehen Sie einen weiteren Share:

An dieser Stelle wechseln wir in die Eigenschaften von dieser Freigabe und konfigurieren in den Einstellungen die erhöhte Verfügbarkeit so, dass diese nicht markiert ist
Update 30. Juni 2015: Wir haben festgestellt, dass diese Einstellung (trotz Empfehlung seitens Microsoft) nicht optimal ist, da es zu Fehlern im Eventlog auf den Hyper-V Hosts bzw. im Hyper-V Cluster kommt. Wird der Share im CA-Modus (also mit Haken) betrieben, tauchen keine Fehler auf. Laut Best-Practice-Empfehlung erfolgt der Schwenk des Quorum bei einem Ausfall eines SOFS-Knoten schneller. Beide Varianten sind transparent, ob es nun schneller oder langsamer geht ist somit auch zu vernachlässigen. Mit eingeschalteter CA erscheinen keine Fehler, dies erleichtert das Monitoring.

Nun kann die Einstellung übernommen werden und die Freigabe ist korrekt konfiguriert.
Quelle: Failover Clustering and Network Load Balancing Team Blog – Configuring a File Share Witness on a Scale-Out File Server
Dieser Vorgang funktioniert auch mit dem oben verlinkten Skript, im oberen Teil bei der Erstellung der Freigabe müssen Sie eine Anpassung bei dem Parameter –ContiniouslyAvailable machen (weitere Infos im Skript), danach wird eine passende Freigabe erstellt.
Nach dieser Anpassung ist der Aufbau im groben komplett. Sie können nun per \\sofs\Share1 oder \\sofs\Share2 auf die beiden Freigaben zugreifen, zusätzlich kann die dritte Freigabe als Quorum-Ablage genutzt werden.

Noch ein paar Worte zu Zugriffszeiten, Benchmarks usw…
Wenn Sie das erste Mal auf die neu erstellten Freigaben zugreifen, kann es einige Zeit dauern, bis das Verzeichnis aufgerufen werden kann und Sie durch die Ordner navigieren können. Dies ist normal, es braucht einen kleinen Moment bis die Verzeichnisse erstmals aufgerufen werden können. Lassen Sie sich hier nicht beunruhigen. Wenn Sie während der Einrichtungs- bzw. Test-Phase das komplette Cluster herunterfahren oder alle Server gleichzeitig neustarten kann es nach dem Start ebenfalls einige Zeit dauern, bis alle Zugriffe wieder problemlos und ohne Verzögerung passieren. Planen Sie hier bitte ebenfalls ein paar Minuten ein, bis alles wieder flüssig und sauber läuft. Im Betrieb sind diese kompletten Ausschaltungen eher selten, daher passiert dies meist bei Simulationen von Problemen oder der kompletten Abschaltung des Dateiserver Cluster.
Wenn Sie einen Performance-Test Ihres neu erstellten Scale-Out File Server machen möchten, fällt Ihnen wahrscheinlich als erstes die Kopie einer Datei auf einen der beiden Shares ein. Dies können Sie zwar machen, lassen Sie sich aber nicht von den Werten abschrecken, die sie während des Kopiervorgangs bekommen. Ein Scale-Out File Server speichert alle Blöcke ungepuffert. Dies wirkt sich bei Datei-Kopier-Operationen negativ aus, bei dem eigentlichen Betrieb des Speichers (der Ablage von VM-Daten) ist dies aber notwendig, damit alle Dateien und Blöcke immer definitiv auf den Platten landen, und nicht in irgendeinem Cache, der bei einem Stromausfall verfallen würde. Ein besserer Benchmark-Test wäre der Betrieb von einigen VMs, in denen mit Hilfe von Last- oder Benchmark-Tools I/O erzeugt wird. Selbst bei diesem Test gibt es wiederum einige Dinge, die beachtet werden sollten. Eine VM alleine reicht nicht, erst die Summe einiger VMs erzeugt (vielleicht) die Art von Last, die im späteren Betrieb auch auf dem System anliegt. Die Tiering-Funktion greift erst dann, wenn eine Umsortierung der Blöcke stattgefunden hat. Dies passiert, wie weiter oben erwähnt, standardmäßig täglich um 1:00 Uhr nachts. Eine Verbesserung der Benchmark-Werte (z.B. bei einem dauerhaften Benchmark) zeigt sich somit erst nach frühestens einem Tag.
Die Nutzung eines Skripts zur kompletten Failover Cluster-Erstellung
Die in diesem Beitrag genutzten Skripte sind fast alles Teilbereiche eines Skripts, welches mein Kollege Carsten Rachfahl bereits in einem Video genutzt und für unsere Zwecke angepasst hat. Das Skript kann ein komplettes Failover-Cluster inkl. Berechnung der Größen, Aufteilung und Erstellung der Datenträger usw. erstellen. Das Skript sowie das ziemlich sehenswerte Video finden Sie hier: Hyper-V-Server.de: Einen bestehenden Scale-Out Fileserver um SSDs erweitern
An diese Stelle ist die Einrichtung im großen und ganzen abgeschlossen. Je nach Umgebung stehen nun noch weitere Schritte an, spontan fällt mir hier noch das Thema Backup ein.
Bei Fragen, der Suche nach Unterstützung oder der Durchführung solch eines Projekts stehen wir Ihnen natürlich gerne zur Verfügung.
![]()
![]()
Der Beitrag Unsere Best Practise-Erfahrungen – Teil 2 – Die Installation und Einrichtung eines Scale-Out Fileserver unter Windows Server 2012 R2 erschien zuerst auf Hyper-V Server Blog.
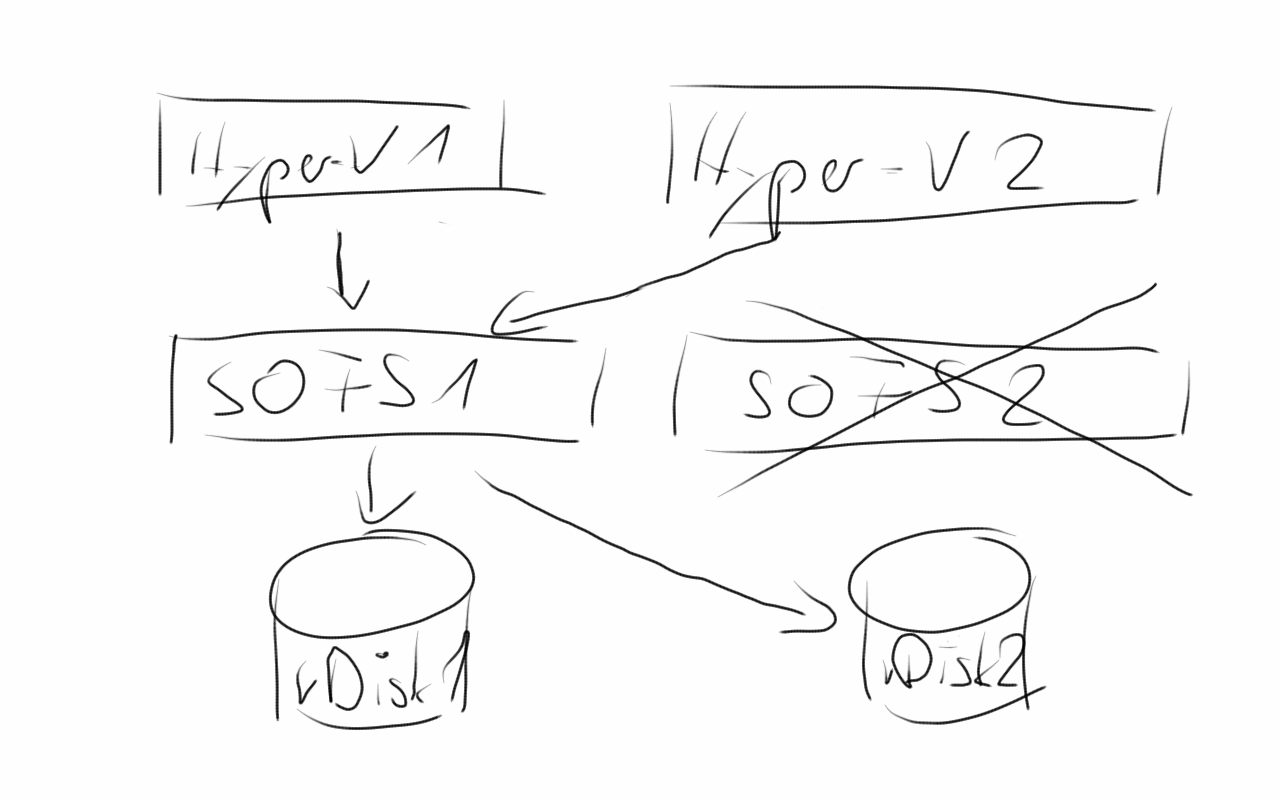
 Wir haben bei unserem Scale Out Fileserver (SOFS) vor kurzem einen Tausch der Server-Hardware durchgeführt. Die alten Systeme werden in Zukunft für unseren Hyper-V PowerKurs genutzt, daher wurden für das Produktivsystem zwei neue Server sowie neue SAS-HBAs angeschafft. Nach einer kurzen Überlegung haben wir festgestellt, dass ein Tausch der Hardware auch im Betrieb möglich sein sollte. Um dies zu verifizieren habe ich den Vorgang dann auch in der Praxis durchgeführt und nachgeschaut, ob dies wirklich so einfach und zuverlässig funktioniert.
Wir haben bei unserem Scale Out Fileserver (SOFS) vor kurzem einen Tausch der Server-Hardware durchgeführt. Die alten Systeme werden in Zukunft für unseren Hyper-V PowerKurs genutzt, daher wurden für das Produktivsystem zwei neue Server sowie neue SAS-HBAs angeschafft. Nach einer kurzen Überlegung haben wir festgestellt, dass ein Tausch der Hardware auch im Betrieb möglich sein sollte. Um dies zu verifizieren habe ich den Vorgang dann auch in der Praxis durchgeführt und nachgeschaut, ob dies wirklich so einfach und zuverlässig funktioniert.






































































































































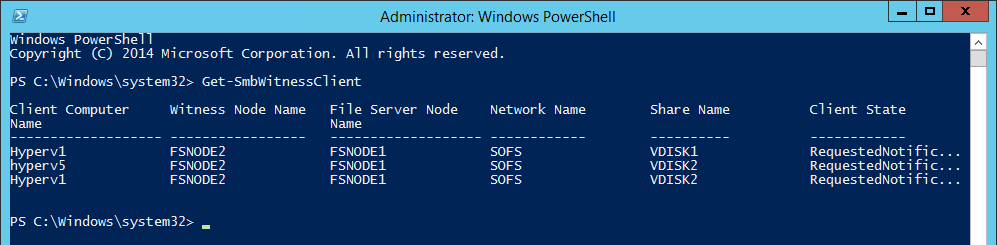
 In diesem Beitrag geht es darum, wie man mit recht einfachen Mitteln einen oder mehrere Scale-Out File Server überwachen kann. Voraussetzung ist, dass Sie einen Scale-Out File Server mit JBODs betreiben. Ein Aufbau mit einem oder mehreren SANs kann zwar auch überwacht werden, hier können aber weniger Informationen ausgelesen werden. Grundlage ist das von Jose Barreto geschriebene PowerShell-Skript Test-StorageHealth. Das Skript verbindet sich mit einem Scale-Out File Server Cluster und überprüft ziemlich viele Dinge, unter Anderem den Status von Festplatten, Enclosures, Volumes usw. Ich habe mit einem zweiten Skript das Verhalten dahingehend ein wenig verändert, dass der Status, der sonst in dem PowerShell-Fenster oder in einer Datei auf dem Server selbst liegt, per Mail an einen Empfänger oder einen Verteiler gesendet werden kann. So kann z.B. jeden Morgen die Mail überprüft werden, ohne das jedes Mal eine Verbindung zu dem Failover Cluster-Knoten aufgebaut werden muss. Aber beginnen wir erst einmal mit dem Skript an sich:
In diesem Beitrag geht es darum, wie man mit recht einfachen Mitteln einen oder mehrere Scale-Out File Server überwachen kann. Voraussetzung ist, dass Sie einen Scale-Out File Server mit JBODs betreiben. Ein Aufbau mit einem oder mehreren SANs kann zwar auch überwacht werden, hier können aber weniger Informationen ausgelesen werden. Grundlage ist das von Jose Barreto geschriebene PowerShell-Skript Test-StorageHealth. Das Skript verbindet sich mit einem Scale-Out File Server Cluster und überprüft ziemlich viele Dinge, unter Anderem den Status von Festplatten, Enclosures, Volumes usw. Ich habe mit einem zweiten Skript das Verhalten dahingehend ein wenig verändert, dass der Status, der sonst in dem PowerShell-Fenster oder in einer Datei auf dem Server selbst liegt, per Mail an einen Empfänger oder einen Verteiler gesendet werden kann. So kann z.B. jeden Morgen die Mail überprüft werden, ohne das jedes Mal eine Verbindung zu dem Failover Cluster-Knoten aufgebaut werden muss. Aber beginnen wir erst einmal mit dem Skript an sich: